深夜,上海张江的某AI实验室里,工程师小王正盯着监控屏上的GPU利用率曲线——代表硬件负载的绿色柱状图在60%的区间反复跳动,这意味着价值千万的算力集群有近四成时间处于空转状态。这种场景并非孤例,全球AI行业正陷入一场集体性焦虑:一边是激增的算力需求,另一边是居高不下的资源浪费率。当科技巨头们竞逐“万亿参数大模型”的军备竞赛时,另一场更为本质的战役正在底层展开——如何让每一焦耳的电力都转化为有效计算?
在这场效率革命中,不同技术路径的碰撞尤为耐人寻味。阿里云选择用自研芯片重构计算架构,将端侧芯片与云端GPU组成协同网络;AWS凭借虚拟化技术深耕硬件余量挖掘,Nitro系统将物理资源损耗压缩至个位数;而九章云极DataCanvas公司这类软件驱动型企业,则通过DataCanvas Alaya NeW智算操作系统和算力包等产品,试图用动态调度算法解开“空闲GPU与排队开发者”的死结。这些看似分化的技术探索,实则共同指向一个目标:突破传统算力供给的物理边界。
硬件之外的战场
翻开任何一家云厂商的技术白皮书,“规模化并行计算”都是显性关键词。阿里云在智慧交通场景中,含光芯片端侧可完成大部分车牌识别,云端GPU则专注复杂行为分析。这种“端侧预处理+云端精加工”的模式,显著提升了单块GPU的并发处理能力,但开发者需重构算法流程以适应异构环境。

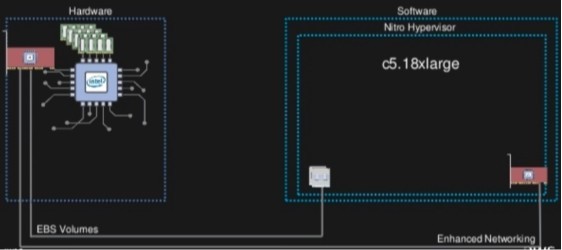
在大洋彼岸,AWS给出了另一种解题思路。采用Nitro系统的EC2在AI推理场景中,相较传统虚拟化方案可承载更多的计算任务。这种硬件卸载策略通过将虚拟化管理、网络安全等功能转移至专用芯片,为AI工作负载提供接近裸机的性能环境。不过,极致虚拟化带来的副作用同样明显:当用户需要调用特定硬件特性时,抽象层反而成为掣肘。
九章云极DataCanvas公司则选择在软件调度层面破局,其自研的DataCanvas Alaya NeW智算操作系统展现出独特的系统级能力,将GPU、CPU等硬件抽象为统一算力单元,配合动态任务拆解,实现跨硬件平台的负载均衡。其算力包产品,则通过以算量计费的模式创新,解决了算力资源浪费、弹性和灵活性不足等痛点,降低了算力使用的预算和价格门槛,在生物计算、工业质检等领域形成“算力集装箱”式供给能力。
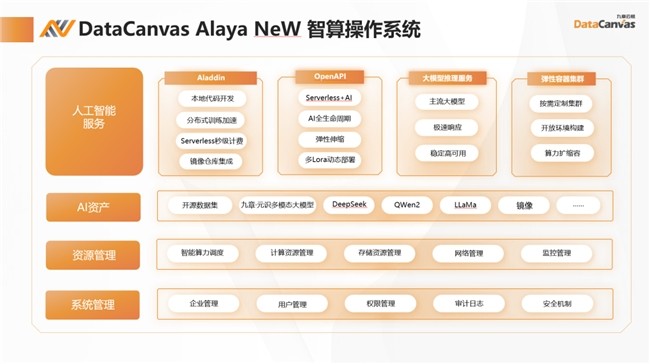
隐性算力的觉醒
GPU利用率低下堪称AI行业的“哥德巴赫猜想”。行业通用的显存管理技术虽能将大模型训练需求大幅压缩,但真正的突破发生在更深层的调度。
九章云极DataCanvas公司的技术创新围绕算力效率提升构建起三位一体的系统级解决方案:在规模化并行应用维度,通过动态任务拆解技术将AI工作流智能分割为预处理、训练、推理等模块,依据GPU/CPU等硬件的异构纳管能力实现负载均衡,突破单一硬件堆砌的效能瓶颈;在GPU利用效率优化层面,基于标准接口实时监测流处理器利用率、显存带宽等核心指标,结合自研的显存碎片整理算法与混合精度自适应调控,显著提升硬件持续负载率;而在计算资源分配机制上,其智能调度引擎可通过“算力包”的弹性封装,将碎片化GPU空闲时段转化为可交易的标准化计算单元。
这三个维度的技术协同,使得企业在不增加硬件投入的情况下,实现系统级有效算力供给的倍增,为破解“算力鸿沟”提供了全新的工程化路径。
效率革命的终局猜想
硬件厂商持续突破物理极限,云服务商深耕规模效应,软件创新者挖掘系统潜能——这三种力量看似竞争,实则构成互补的“铁三角”。
某天,一家智能工厂同时调用AWS竞价实例、阿里云端侧芯片、九章云极DataCanvas公司的DataCanvas Alaya NeW智算操作系统来优化质检流程,这个略显复杂的技术组合,恰折射出行业真相:算力平权不是非此即彼的选择,而是多元技术路线在对抗与妥协中形成的动态平衡。
这场静默革命的终极目标,是让算力资源像水电般自由流动。当西部风电场的光伏板与东部实验室的GPU集群形成能源-算力闭环,当中小开发者无需抢购整卡也能获得精准算力供给,真正的智能时代才算降临。正如某AI工程师在技术论坛的留言:“我们不需要乌托邦,只要明天能比今天多获得10%的有效算力。”
在这场没有终点的效率革命中,每个技术路径都是通向未来的拼图。当硬件堆砌触及天花板时,或许正是DataCanvas Alaya NeW智算操作系统这类系统级软件创新开启新纪元的时刻。
本文属于原创文章,如若转载,请注明来源:行业观察|AI下半场的云暗战:从算力内卷到效能革命https://pad.zol.com.cn/977/9773453.html